What is RAG? A Guide to Retrieval-Augmented Generation
Why make your LLM remember everything when it can simply look it up?
Large Language Models (LLMs) are brilliant at generating text, but they face fundamental limitations.Their knowledge is static, frozen at the time of training, which can lead them to "hallucinate" facts. Updating an LLM with new information requires resource-intensive retraining or fine-tuning.
Retrieval-Augmented Generation (RAG) solves this by giving the LLM a live external brain. Instead of just asking the LLM a question directly, a RAG system first performs a search (the "Retrieval" step) on an external knowledge source (like a textbook, a company's internal wiki, or the internet). It finds the most relevant information and then provides it to the LLM along with the original question. The LLM then uses this provided context to formulate its answer (the "Generation" step).
How Does RAG Work? The Core Components
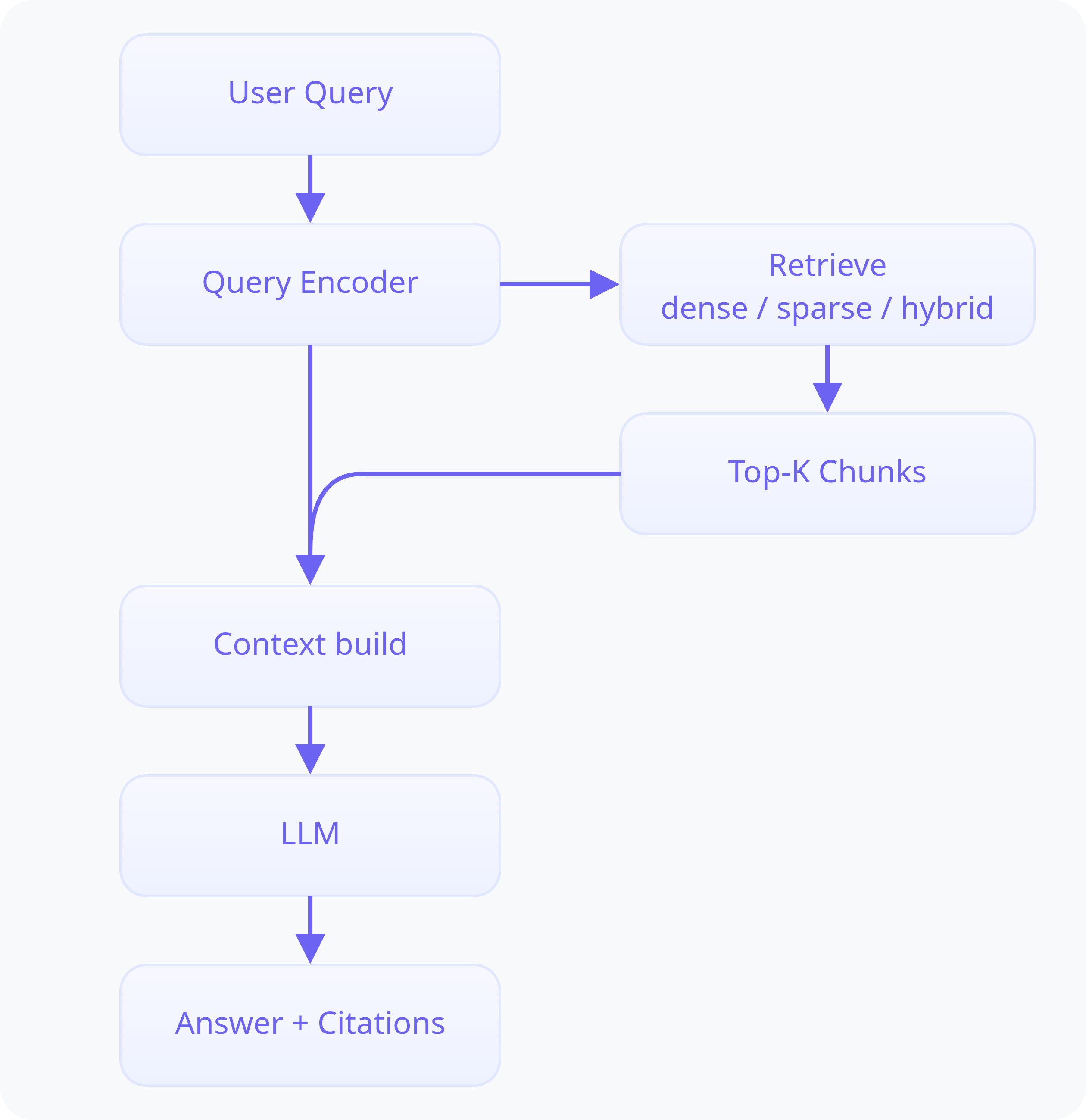
A RAG system coordinates three distinct components to deliver fact-grounded responses.
The Indexer and Vector Store
The indexer is the component responsible for creating the searchable "brain" of your RAG system. This happens via an ingestion pipeline, an offline process that transforms your raw documents into a structured knowledge base. While it runs once for the initial setup, this pipeline can be re-run to add new documents or update existing ones. This process involves three key steps:
- Chunking: Documents are broken down into smaller, manageable pieces
- Embedding: Each chunk is passed through an embedding model to convert its semantic meaning into a numerical vector
- Loading: These vectors and their corresponding text content are loaded into a Vector Store
The Vector Store is a specialized database optimized for extremely fast vector search. It uses an Approximate Nearest Neighbor (ANN) index, to quickly find document vectors that are most similar to a given query vector.
The Retriever
The retriever acts as the system's information scout. Its job is to understand the user's query and find the most relevant pieces of information from the knowledge base.
- Encodes the query into a vector (dense) or term-weighted list (sparse)
- Searches the knowledge base for relevant chunks
- Returns a ranked list of candidates with metadata
Common Retriever Types
- Dense Retrievers: Use trained encoders to map queries and documents into a shared vector space, enabling searches based on semantic meaning rather than just keywords
- Sparse Retrievers: Classic information retrieval (IR) methods like BM25 that match keywords and term frequency
- Hybrid Retrievers: Combine the strengths of both dense and sparse methods
How is "Relevance" calculated in Vector Search?
When a dense retriever converts a query and documents into vectors, the system needs a way to measure "closeness" in this high-dimensional space. The most common method is Cosine Similarity.
Instead of measuring the straight-line (Euclidean) distance between vectors, cosine similarity measures the angle between them. A smaller angle means the vectors are pointing in a similar direction, indicating high semantic similarity, regardless of their magnitude.
The formula is:
- A and B are the vectors for the query and a document chunk
- A value of 1 means the vectors are identical in orientation (perfect match)
- A value of 0 means they are orthogonal (unrelated)
- A value of -1 means they are opposite (opposite meaning)
In practice, this allows the retriever to find documents that discuss the same concepts as the query, even if they don't use the exact same keywords.
The Generator
The generator is the LLM itself. It receives an "augmented prompt" that contains both the original user query plus the relevant data chunks provided by the retriever. By using this combined context, the LLM can generate a comprehensive, fact-grounded answer that directly addresses the user's needs while minimizing hallucination.
Chunking strategies
Chunking is the process of breaking large documents into smaller pieces and is fundamental to a RAG system's success. The right strategy ensures that the retrieved context is both relevant and coherent. While many techniques exist, they generally balance simplicity against semantic coherence.
While it may sound trivial, the method used for chunking is one of the most critical decisions in a RAG system. A naive approach, like simply splitting the text every 512 tokens, is a leading cause of poor RAG performance in practice.
- Too large: retrieval returns irrelevant blobs with lots of noise (e.g., a financial report query returns the entire Q1 section)
- Too small: retrieval misses context, forcing the LLM to guess relationships between fragments
- Misaligned splits: break code, formulas, or semantic units, leading to incoherent answers
Fixed-Size Chunking
This simple approach splits text into chunks of a predefined length (e.g., 512 tokens).
- Pros: Easy and fast to implement, providing a solid baseline
- Cons: Can awkwardly split logical units, breaking apart sentences or ideas. This loss of local context is a significant risk
Semantic Chunking
This method splits documents along logical boundaries, such as headings, sections, or sentences, and keeps related content like code blocks intact.
- Pros: Better preserves the original meaning and structure of the document
- Cons: Results in variable chunk lengths and may require extra tooling
Recursive Splitting
This strategy attempts to split text along a prioritized list of separators (e.g., section headings, then paragraphs, then sentences). It recursively works through the separators until the resulting chunks are below a maximum size limit.
- Pros: Lets you retrieve a fine chunk and still show parent context, making it highly effective
- Cons: Can be more complex to configure than simpler methods
Sliding Window
This technique creates overlapping chunks to ensure that context is preserved across chunk boundaries. It is particularly useful for dense content where local continuity is critical, such as in code or mathematical formulas.
- Pros: Excellent for maintaining context in sequential data.
- Cons: Creates redundant data, increasing the size of the vector store.
Summary Common chunking strategies
| Strategy | How it works | Pros | Cons | Good for |
|---|---|---|---|---|
| Fixed-size | Split into N tokens (e.g., 512) | Simple, predictable | Ignores semantic boundaries | Uniform text, minimal structure |
| Semantic chunking | Split by sentences/paragraphs using embeddings | Preserves meaning | Irregular sizes, possible token budget waste | Research papers, legal docs |
| Recursive splitting | Split by semantic markers, then recursively by token limit | Balanced context & size | Implementation complexity | Technical docs, mixed media |
| Sliding window | Overlapping fixed-size chunks (e.g., 512 with 128 overlap) | Retains cross-chunk context | Redundancy inflates index | Narrative text, FAQs |
Benefits of Using RAG
RAG is more than just a clever architecture; it's a practical solution to some of the most significant challenges facing LLMs today. By grounding generation in verifiable, external facts, RAG systems:
- Reduce Hallucinations: The model is guided by real data, not just its parametric memory
- Enable Knowledge Updates: You can update the knowledge base simply by adding new documents, no expensive retraining required
- Provide Explainability: Because the system tracks which data chunks were used to generate an answer, it can provide citations. This allows users to verify the information and trust the model's output
While building a production-ready RAG system requires careful optimization of retrieval quality and document processing, its principles are essential for creating the next generation of trustworthy AI tools.
📄️ RAG
Learn how Retrieval-Augmented Generation (RAG) enhances LLMs by connecting them to external knowledge, reducing hallucinations and enabling real-time updates.
🗃️ Model Context Protocol
1 item