Vector Databases: The Engine for AI-Powered Search
TL;DR
- What is a vector database? A specialized database built to store, manage, and search high-dimensional vector embeddings, which are numerical representations of data like text, images, or audio.
- Why are they needed? Traditional databases are slow and inefficient at finding similar items in complex, high-dimensional data, a problem known as the "curse of dimensionality."
- How do they work? They use Approximate Nearest Neighbor (ANN) algorithms to find "good enough" matches almost instantly, trading perfect accuracy for significant speed improvements.
- What are the key use cases? Vector databases are essential for modern AI features like semantic search, recommendation engines, image recognition, and Retrieval-Augmented Generation (RAG) for LLMs.
- What about hybrid solutions? Systems like PostgreSQL (with
pgvector) and Elasticsearch now offer vector search capabilities, providing a convenient option for smaller-scale needs, though dedicated databases offer better performance at scale.
Vector databases are specialized databases built to efficiently store and retrieve high-dimensional vectors. These vectors, known as embeddings, are numerical representations of complex data like text, images, and audio. As AI applications in natural language processing (NLP) and computer vision become standard, vector databases provide the essential infrastructure for features like semantic search, recommendation engines, and generative AI.
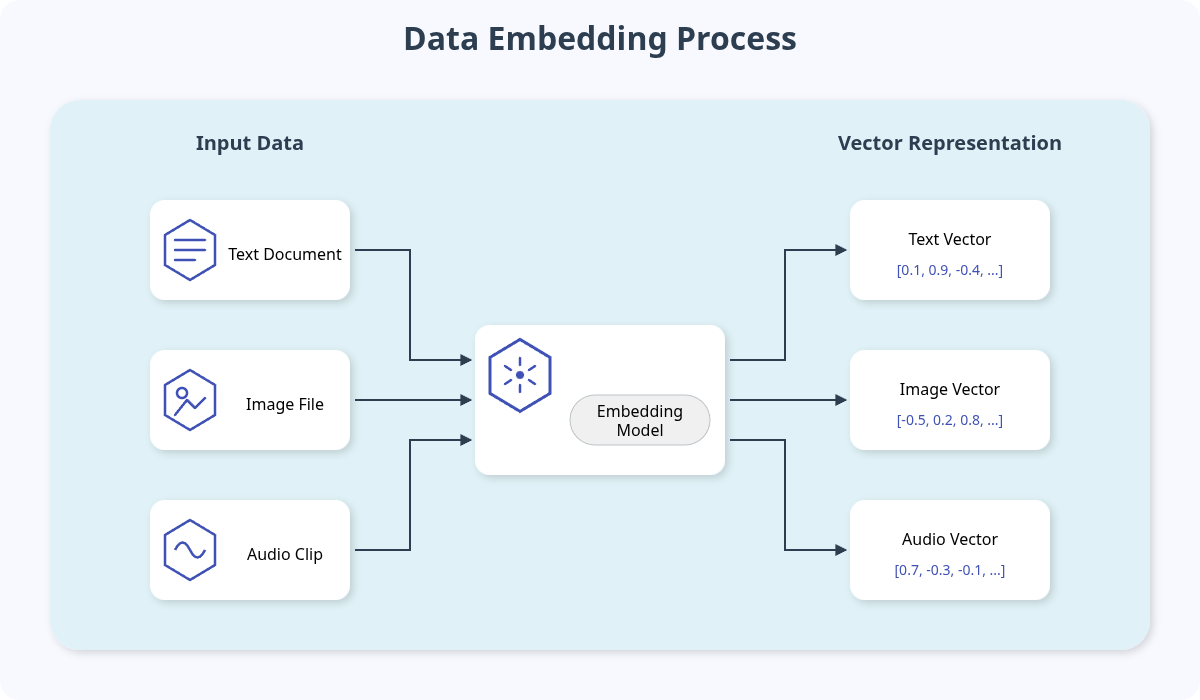
What Are Vector Embeddings?
Before understanding the database, it's essential to understand the data it stores. Vector embeddings are the foundation of modern AI, created when machine learning models convert unstructured data into a meaningful numerical format.
This process allows a model to capture the semantic or contextual meaning of the data. For example:
- Text: A sentence like "What is the capital of France?" is converted into a vector that captures its semantic meaning. The vector for "Which city is France's capital?" would be very close to it in the vector space.
- Images: An image of a golden retriever is converted into a vector. Another image of a different golden retriever would generate a vector that is mathematically close.
- Audio: A snippet of a song is converted into a vector that represents its melody, rhythm, and instrumentation.
These embeddings position related concepts close together in a high-dimensional space, making it possible to find them through mathematical calculations.
Why Traditional Databases Fall Short
Querying for similarity in a high-dimensional space is computationally expensive. A traditional database attempting to find the "closest" vector to a query would need to compare the query vector to every single vector in its dataset. This process, known as an exhaustive search or k-Nearest Neighbor (k-NN) search, becomes impossibly slow as the dataset grows.
This challenge is often called the "curse of dimensionality." As the number of dimensions increases, the volume of the space grows exponentially, making data points sparse and distance calculations increasingly complex. A simple index on a single column is useless when you have hundreds or thousands of dimensions to consider simultaneously.
The Rise of Hybrid Solutions
The line between traditional and vector databases is blurring. Many popular data systems now offer extensions or native features for handling vector search, providing a convenient alternative to adopting a new, specialized database.
- PostgreSQL: The
pgvectorextension allows developers to store and query vector embeddings directly within a familiar relational database using SQL. - Elasticsearch & OpenSearch: These powerful search engines have incorporated native vector search capabilities, enabling teams to combine traditional keyword filters with modern semantic search in a single system.
These hybrid solutions are practical for teams looking to use existing infrastructure, especially for smaller applications.
| Feature | Dedicated Vector Database (e.g., Pinecone, Weaviate) | Hybrid Solution (e.g., PostgreSQL with pgvector) |
|---|---|---|
| Performance | Optimized for ultra-low latency; scales to billions of vectors. | Good for smaller scale; may face latency issues with large datasets. |
| Convenience | Requires adopting a new system and data pipeline. | Uses existing infrastructure and SQL knowledge. |
| Features | Advanced filtering, real-time indexing, specialized APIs. | Basic vector search; relies on existing database features. |
| Best For | High-performance, large-scale production AI applications. | Prototypes, smaller projects, teams consolidating their tech stack. |
Table 1: Comparing Dedicated Vector Databases and Hybrid Solutions
While convenient, these integrated systems can struggle with performance and scalability compared to purpose-built vector databases. A dedicated engine is engineered from the ground up for vector search and is optimized to handle billions of vectors with millisecond latency. The choice depends on your specific needs: the convenience of an all-in-one system versus the high performance of a specialized database.
How Vector Databases Work: Speed Through Approximation
Vector databases solve the performance problem by trading perfect accuracy for massive speed gains. Instead of finding the absolute nearest neighbors, they use Approximate Nearest Neighbor (ANN) algorithms to find "good enough" matches almost instantly.
The workflow consists of two primary stages: indexing and querying.
1. Indexing
When vectors are added to the database, they are organized using a specialized ANN index. This index creates a data structure, like a map, that groups similar vectors together. This pre-computation makes searching much faster because the database doesn't have to scan every single item at query time.
Common ANN indexing algorithms include:
- HNSW (Hierarchical Navigable Small World): Builds a multi-layered graph. Upper layers have long-range connections for quickly traversing the vector space, while lower layers have shorter connections for fine-grained search within a specific region.
- IVF (Inverted File Index): Clusters vectors into partitions. A query is only compared against vectors in the most promising partitions, which dramatically reduces the search scope.
- LSH (Locality-Sensitive Hashing): Uses hash functions to group similar items into the same buckets, making it fast to find potential matches.
2. Querying
When a query vector is received, the database uses the ANN index to quickly navigate to the most relevant region of the vector space. It then performs distance calculations (like Cosine Similarity or Euclidean Distance) on a small subset of candidate vectors to find the closest matches.
This approach returns results that are highly likely to be the true nearest neighbors in a fraction of the time an exhaustive search would take.
Common Use Cases for Vector Databases
Vector databases are the backbone of many AI-powered systems. Here are some use cases:
- Semantic Search: Go beyond keyword matching. Users can search with natural language, and the system returns results based on conceptual meaning, not just shared words.
- Recommendation Engines: Find similar products, articles, or songs by comparing their vector embeddings. If a user likes a product, the system can recommend others that are "close" to it in the vector space.
- Image and Video Search: Search for visually similar images. You can use an image as a query and find others that contain similar objects, scenes, or styles.
- Retrieval-Augmented Generation (RAG): Enhance Large Language Models (LLMs) by giving them access to relevant, up-to-date information. A vector database can quickly retrieve documents related to a user's prompt, which the LLM then uses to generate a more accurate and context-aware response.
- Anomaly Detection: Identify outliers in data by finding data points that are far away from any established clusters in the vector space.
Key Features of a Modern Vector Database
When evaluating a vector database, consider these essential features:
- Scalability: The ability to handle billions of vectors and high query throughput.
- Performance: Low-latency queries (typically in milliseconds) and efficient index building.
- Filtering: The ability to combine vector similarity search with traditional metadata filters (e.g., "find images similar to this one, but only those created in the last month").
- Developer Experience: Clean APIs, comprehensive SDKs (like Python and JavaScript), and simple integration with machine learning frameworks.
- Deployment Options: Flexibility to deploy as a managed cloud service, on-premises, or as an open-source solution.
Popular vector databases include managed services like Pinecone and open-source solutions like Weaviate, Milvus, and Chroma.
Frequently Asked Questions (FAQ)
What is the main difference between a vector database and a traditional database?
The main difference is the type of query they are built for. Traditional databases (like SQL or NoSQL) are designed for structured data and exact-match lookups. Vector databases are designed for high-dimensional data and perform similarity searches to find the 'closest' items.
Is a vector database a type of NoSQL database?
While vector databases share some characteristics with NoSQL databases (like scalability and flexible schemas), they are a distinct category. Their core architecture is built around specialized indexing algorithms (like HNSW or IVF) for Approximate Nearest Neighbor (ANN) search, a capability not native to most NoSQL systems.
Do I always need a vector database for AI applications?
Not always. For small-scale projects or prototypes, you can perform vector searches using libraries like Faiss or Scann directly in your application's memory. However, a dedicated vector database becomes essential for production systems that require scalability, data persistence, real-time updates, and advanced features like filtered search.
What is Retrieval-Augmented Generation (RAG) and how do vector databases enable it?
Retrieval-Augmented Generation (RAG) is a technique that improves the accuracy of Large Language Models (LLMs) by providing them with external knowledge. A vector database stores and retrieves relevant data (e.g., company documents, a knowledge base) based on a user's prompt. This retrieved context is then passed to the LLM along with the original prompt, allowing it to generate more factual and up-to-date answers.